|
Spring 2024 was a semester of many milestones across all domains of my work: research, service, and teaching. On research, my first-ever-paper with my advisee and PhD student received a revision opportunity. I submitted two other major revisions that I * actually * thought improved the papers, which is not always the case. On service, I was invited to the editorial review boards (ERB) of two journals in marketing, including the Journal of Marketing whose new efficient review process and focus on publishing novel research I admire. I received my first ever reviewing recognition as one of the best reviewers for the Journal of the Academy of Marketing Science. Importantly, as the PhD coordinator (with Rosanna) at Gies, I got to work with PhD students on their goals more closely, including conversations about what it means to get a PhD in marketing right now. On teaching, I mentored MS teams on their mini research projects with me the entire semester that led to some cool findings! This was one of my best marketing analytics cohort since 2020. Here are some reflections on each area of my work, and how I continued challenging common-wisdom (often even my own beliefs): Research with PhD students and mentoring: Junior faculty are often given the advice to not work with PhD students, at least not as their primary advisor. It takes too much time. In hindsight, perhaps this advice is prudent. As most things in my life, I serendipitously was matched with a student who wanted to do empirical work the year I joined Gies. I was the only empirical quant person in the group and so, I advised the student's first and second year papers; these are also the critical stages of a PhD when you can potentially get "kicked out" and so, also the time when I needed to have hard conversations with the student (and with the department). While much of the work with students is research-related, a ton of it is also decoding to them what a PhD and academic life mean, and the philosophy of it. Were there moments I wanted to give up? Sure. Was the first rejection on the paper we submitted hard? Always. Were we able to re-work it majorly and get to a revision opportunity? Gratefully, yes. In hindsight, perhaps I had to project-manage much more than I'd have liked or had ever needed my advisors to do for me. Yet, there were some rewarding moments making it worth it. The biggest lesson I learned is to have the hard conversations and to work with the student's goals and aspirations, and not your goals and aspirations for them -- or how you would've done things if this was your PhD. As my colleague Maria Rodas and I often discuss, working with PhD students is a service. As a pre-tenure faculty, your work with PhD students likely won't contribute a lot to your tenure. In fact, it may take up more time and effort (and emotional energy) than you can afford. But it's also a responsibility for us to move our field forward and pass on what we have learned. Caveat: I should say that I have had to cut down mentoring MS students on research ever since my work with the PhD student scaled up. Time and priorities can be managed. I also cut down my travel from November to April, until all my major revisions were sent back in. Research and reviewing (and the synergies) Junior faculty are often given the advice to review selectively, or only review for journals they hope to be on the ERBs of. It takes too much time. Reviewing makes you a better researcher in my view. Others can perhaps give a ton more reviewing advice on how to write good reviews, but I will share 3 things that have helped me use reviewing feedback as a way to improve my own research and reviews:
Similarly, I learned a lot from giving others feedback on their papers through tangible and intangible ways including discussing my peer and friend's Shrabastee and her co-authors work on Goodreads at UCSD recently (video, paper). Teaching (and synergies with research and mentoring) Junior faculty are often given the advice to not to take on too many new preps. It takes too much time. While I have been lucky to be able to stack my teaching and get an extended 2-0 teaching load (3-0 is more common), I have never shied away from a new prep. I have taught marketing analytics to undergrads (BADM 361), marketing analytics to masters (BADM 591), two different online iMBA courses (that also have a Coursera version with over 67k learners here and here), and an advanced marketing management course to undergrads (BADM 420) that earned me the Poets&Quants' Best Undergrad Professor honor. Again, others can offer much more teaching advice and great content (e.g., I often refer to Ken and Dan's course materials here and Avi's quant marketing PhD seminar list here among others), I want to emphasize synergies between research and teaching that have helped me:
Finally, across all domains, it's helped me to SHOW UP to things, be part of a community, and help propel others as you have been helped along the way. Coming soon: Next week, I will post about the exciting projects my MS students put together this semester including framing questions about collecting data to analyze topics like how do Boeing crashes impact its stock prices and order cancellations, and how Taylor Swift's appearances in NFL games impacts the social media following of Travis Kelce and related influencers. More soon!
0 Comments
 The American Marketing Association's (AMA) Retail & Pricing Special Interest Group (RAPSIG) interviewed me about my research and teaching, as their incoming Vice President of Outreach. Read more here: amarapsig.org/?page_id=2324.  For the last two years, I have been tracking and sharing my data in these blog posts for 2022 and 2021. This year, I continued the tradition. I primarily track two types of data: Work (e.g., hours logged on research, reviewing, teaching) and health (e.g., daily workouts, calories consumed). Recap: In both 2021 and 2022, I spent ~900 hours working on my top 5-6 research projects based on reports generated by an app called Toggl. Of course, all this is based on the projects and hours I am able to track in Toggl subject to some measurement error. I completed over 250 hours of workouts each year, dropping 20+ lbs in 2021 then maintaining in 2022. How does 2023 look? @ work: This year, I exceeded my research input of the last two years. I submitted 6 new/revised submissions (relative to 4ish last two years), including a manuscript with a PhD student and a solo-authored paper. I spent 1,000+ hours on my top 4 projects with over 70% of that on one paper (phew!). I spent fewer hours on exploring new ideas than I have in the past -- mostly doing so in the Spring semester (no teaching). Unlike last few years, when I had to kill many new ideas, I was able to see this one through -- and moved it into a "real" project bucket to become my 2nd biggest project investment this year. Importantly, I noticed that my hours spent on reviewing/writing referee reports doubled compared to last year. That must be a good thing, right? I don't usually report this but will be fun to track over the long-term.... @ the gym: I increased my focus on weightlifting and was able to achieve new PRs of 200 and 300 lbs on squats and hip thrusts in June (!!) despite several health challenges throughout the year. I incorporated more yoga (although steady state cardio and HIIT both took a hit this year for me). Yoga has been a lovely addition to my life -- and I will not attempt to capture its impact in numbers. -- As always, quality over quantity; so I cannot end this post without mentioning some of the opportunities for growth this year that are not captured by the data. Many in-depth conversations with peers and colleagues, opportunities to visit other groups (Reichman and Tel Aviv University in Israel, Washington University in St. Louis, Michigan Ross, and INSEAD in France as well as conferences @ UT-Dallas and Temple), and to continue to push past many rejections and risky revisions. Other highlights of the year include my interactions with students, co-chairing our PhD committee, organizing mental health workshops for students, and being part of their convocation experience esp. for the iMBA graduates. -- More stats and how I track my data below: 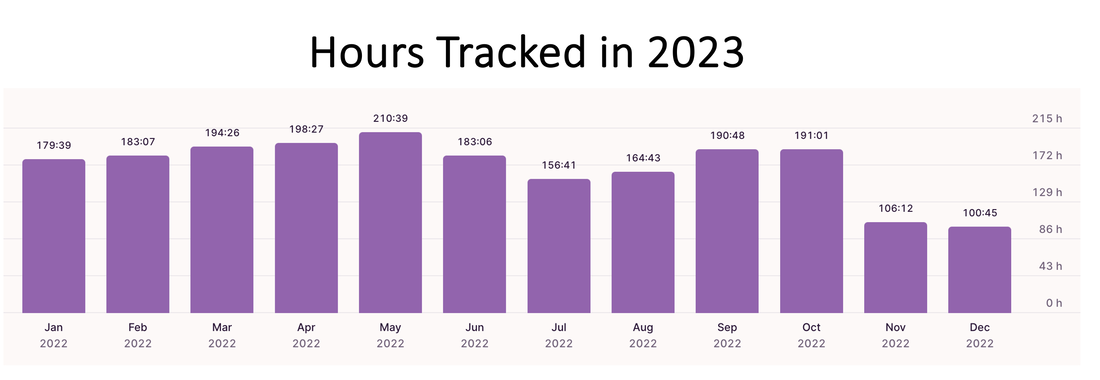 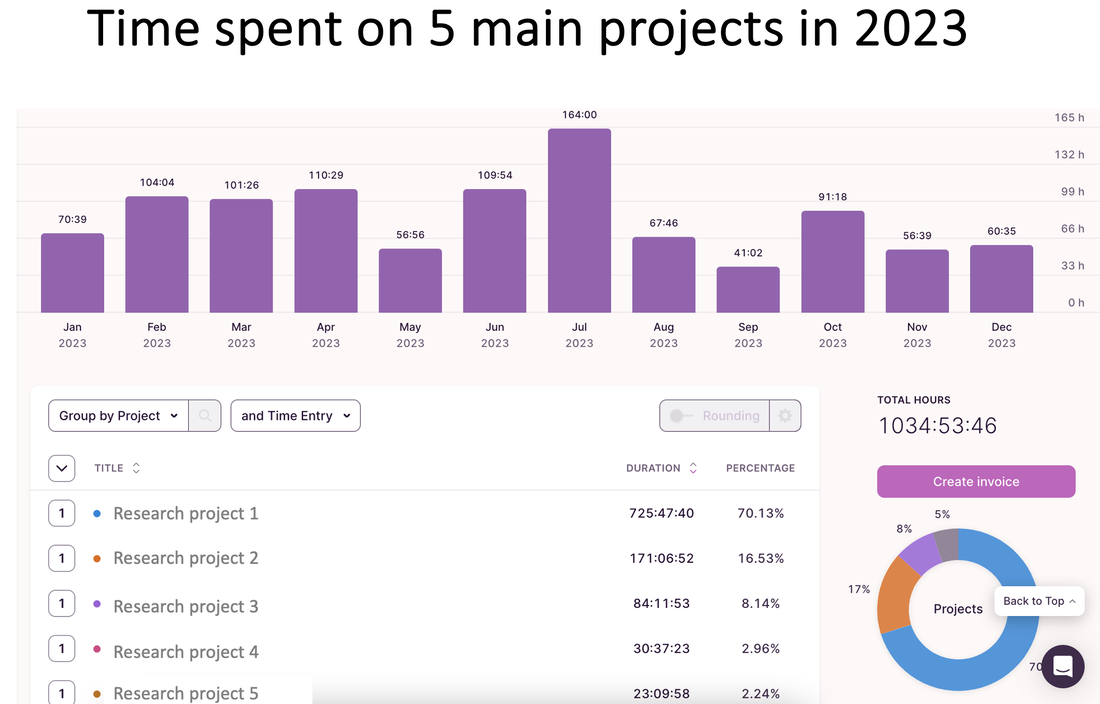 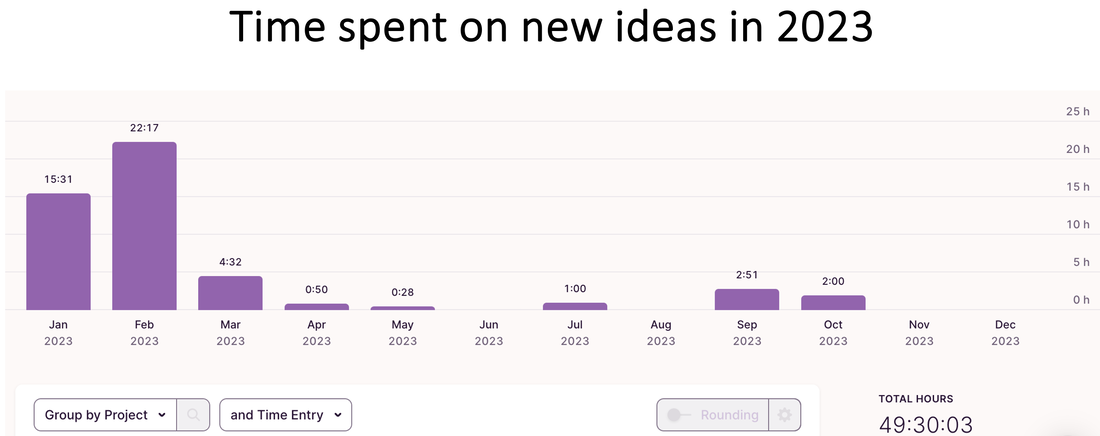 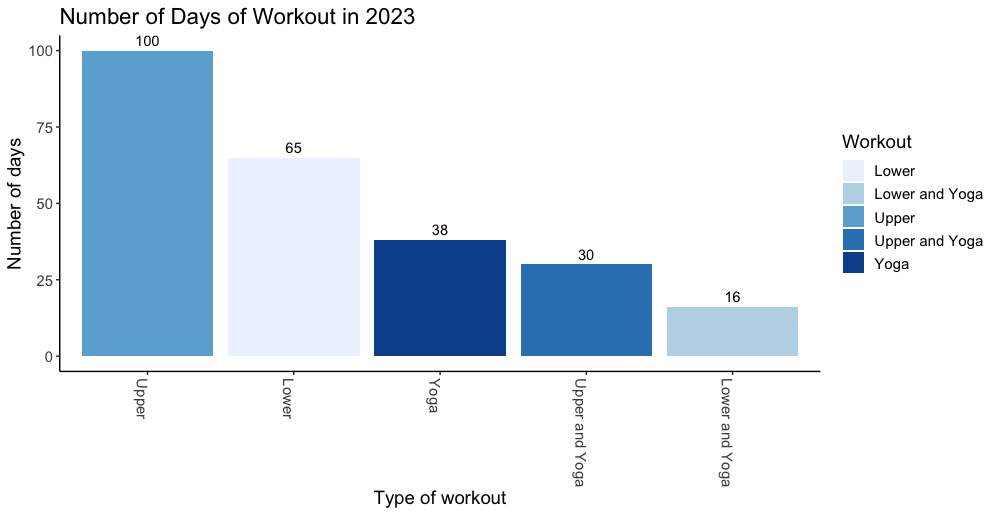 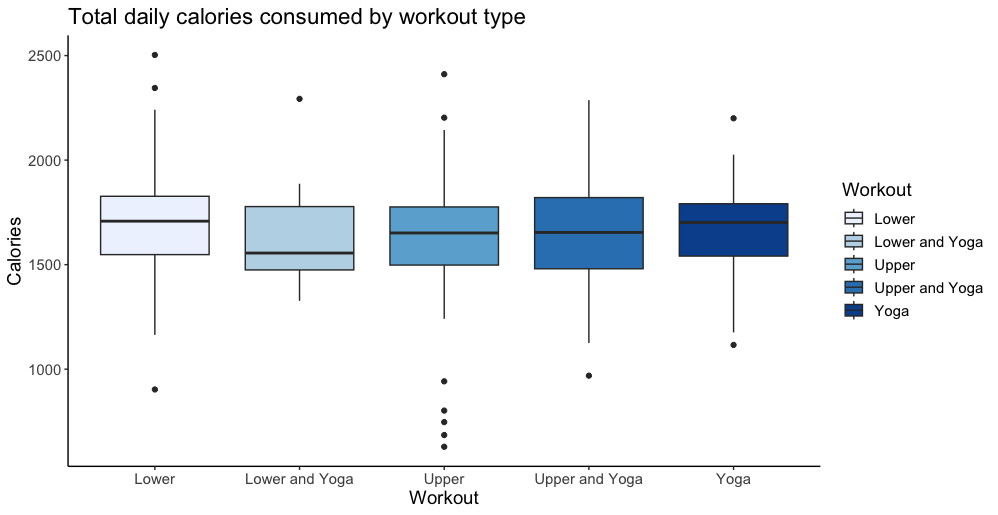 Bonus: One new interesting comparison I plotted this year was my actual calorie intake relative to the goals I set in the MyFitnessPal app (e.g., typical goals will be between 1600-2000 calories per day). I noticed that I was mostly eating below my goal (!!): 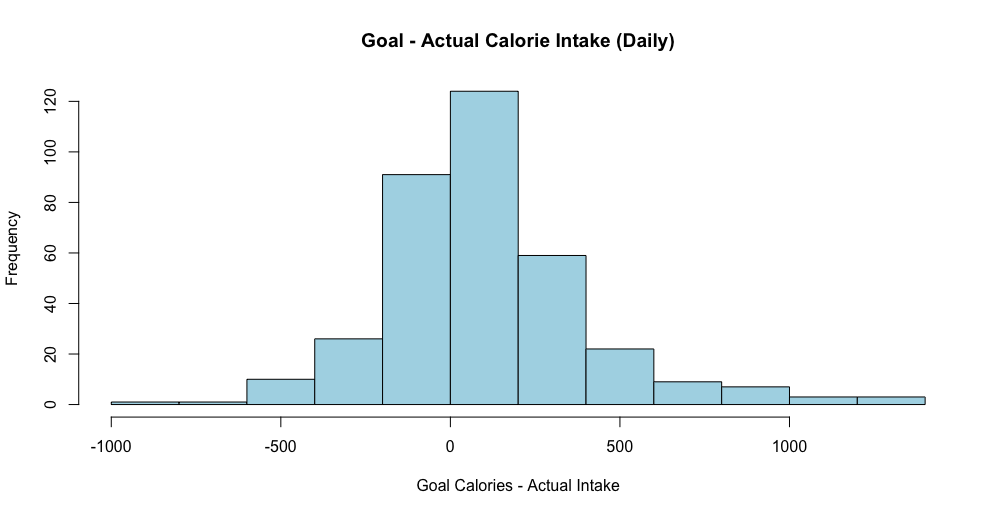 Note: These data are combined from various sources. The project hours data come from Toggl. The workouts data come from 3 different apps - Strong, Trainerize, and my Mindbody app I use to book yoga classes. The calorie data come from MyFitnessPal which I have been using to track my food for over 900 days. Other stuff I track but don't report is my reading lists on Goodreads (made it half way to my reading goal this year) and my Italian lessons on Duolingo (proud 250 days so far).
-- If you find these posts useful, please let me know. Often, the work academics do can appear "black box" to others who can tend to feel that our only job is what we do in the classroom and that we get "summers off" (nice joke). So this is my attempt to share what we do in our job, which is more like an identity or a lifestyle rather than a job. My plan for 2024? I might move to a more intuitive approach to health and work i.e., less tracking... But we will see.  I knew I wanted to be a business school professor when… "I never wanted to be a professor. I found my way to this career – which is now truly my dream job – through many winding paths and serendipity."
Click here for the complete interview on Poets & Quants' website. It’s time for the academic job market season again. I have been helping our students practice their AMA conference-style 30-minute job interviews.
Here’s some thoughts and general advice I compiled in a Twitter thread recently:
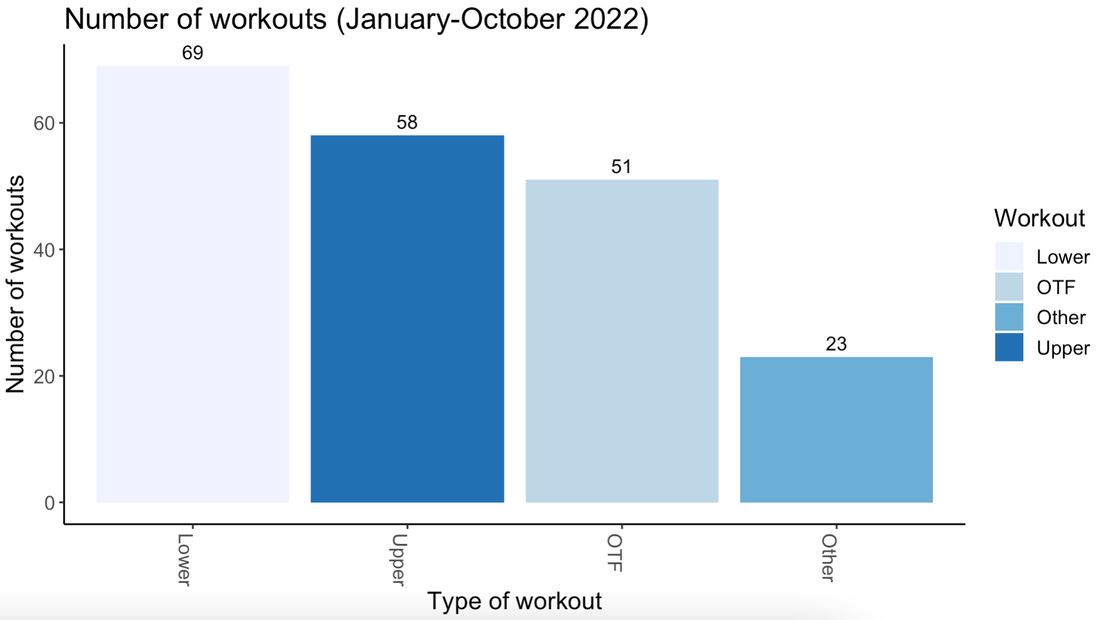
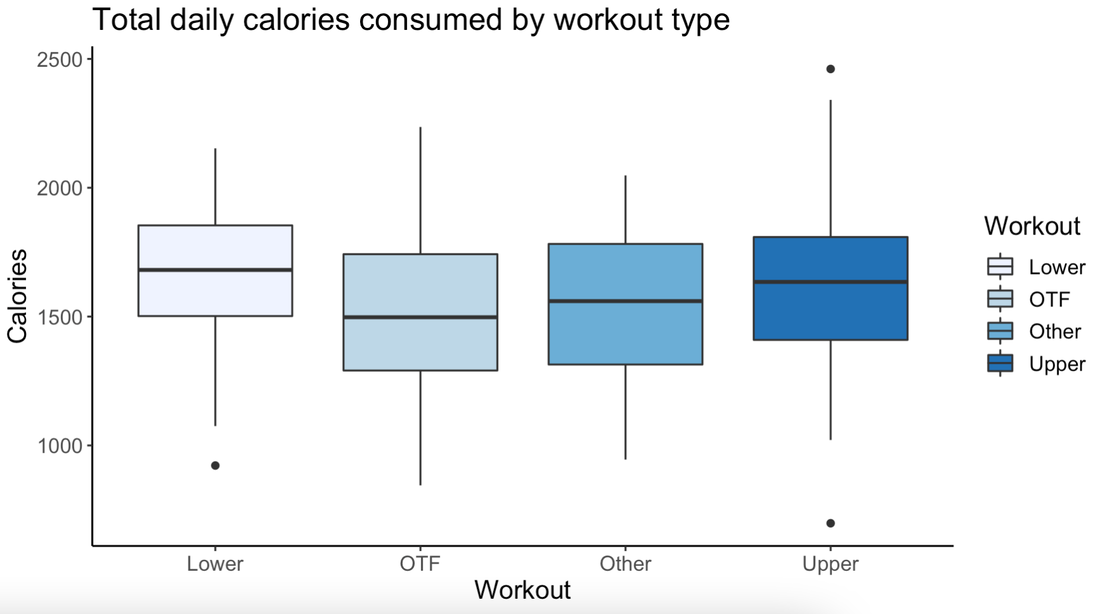
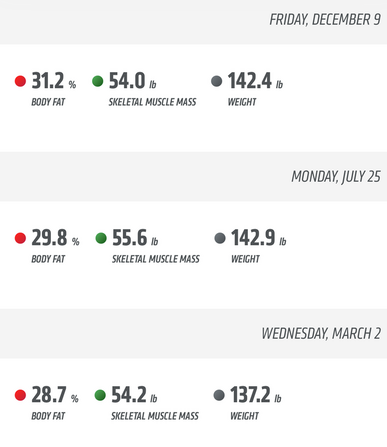
Most important, take care of yourself and be kind! Last year, I started tracking my data and wrote a blog post about it. I primarily track two types of data: Work (e.g., hours logged on research, teaching) and health (e.g., daily workouts, calories consumed, body measurements). 2021 stats: In 2021, I spent 932 hours working on my top 6 research projects. I completed over 250 hours of workouts and lost over 20 lbs with a 5% drop in body fat. It’s a bit soon to summarize 2022 and the December data aren’t in yet – but I wanted to take an early look at the year (minus December). 2022 stats: In 2022, so far, I spent 818 hours working on my top 5 projects with an additional 59 hours exploring 7-8 new ideas of which only 2 have continued and stuck with me. Killed 5 new project ideas this year! Taught at least twice as many classes as 2021. Of course, all this is based on the projects and hours I am able to track subject to some measurement error. Many "new ideas" never make it to this set. So these numbers should be interpreted as lower bounds. My key trends @ work:
My key trends with fitness: With fitness, my main goal this year was maintenance. I continued to keep the 20lbs I lost in 2021 off and maintained my 250 or so workouts with lots of long runs/cardio in the first half of the year and transitioning to mostly strength workouts in the second half. Overall – what a year it’s been! More details below for those who love to see the data as much as I do. (1) Expanding the pie: 30% more hours in 20222022 vs. 2021 data! Logged more hours in the summer this year compared with 2021. Thanks to Thanksgiving, the month of November in both years was pretty good for home/family time.  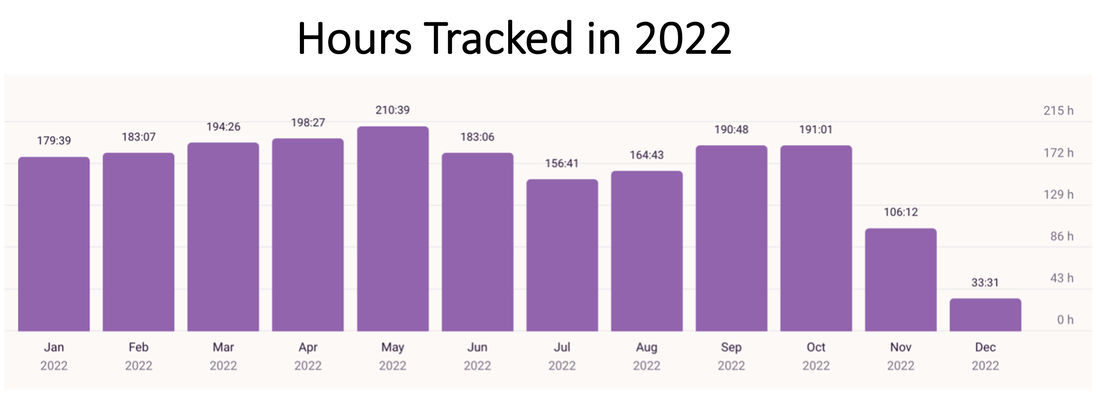 (2) Exploitation-exploration trade-off Invested primarily in my 5 main projects in the early part of the year with over 60% time on just 2 of them. Both are now (re)submitted. Fingers crossed! 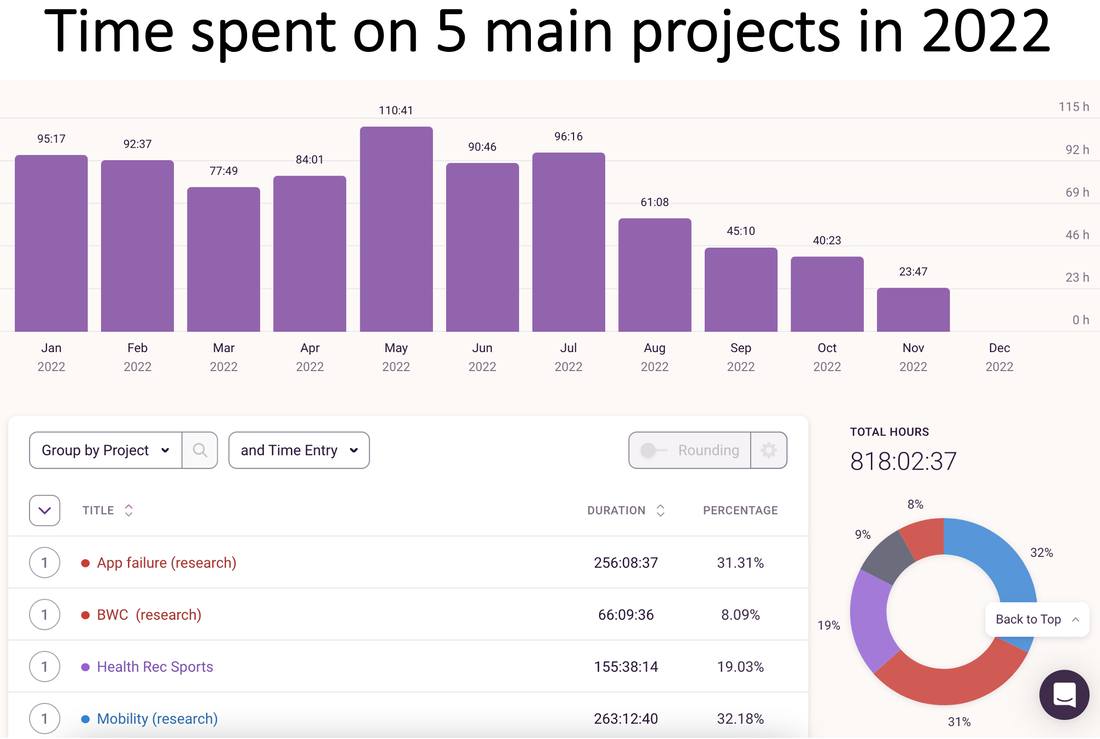 Tried out new ideas and teams more in the second half of the year. I am pretty sure I didn't track my time on these ideas properly but spent about 59 hours as a lower bound: 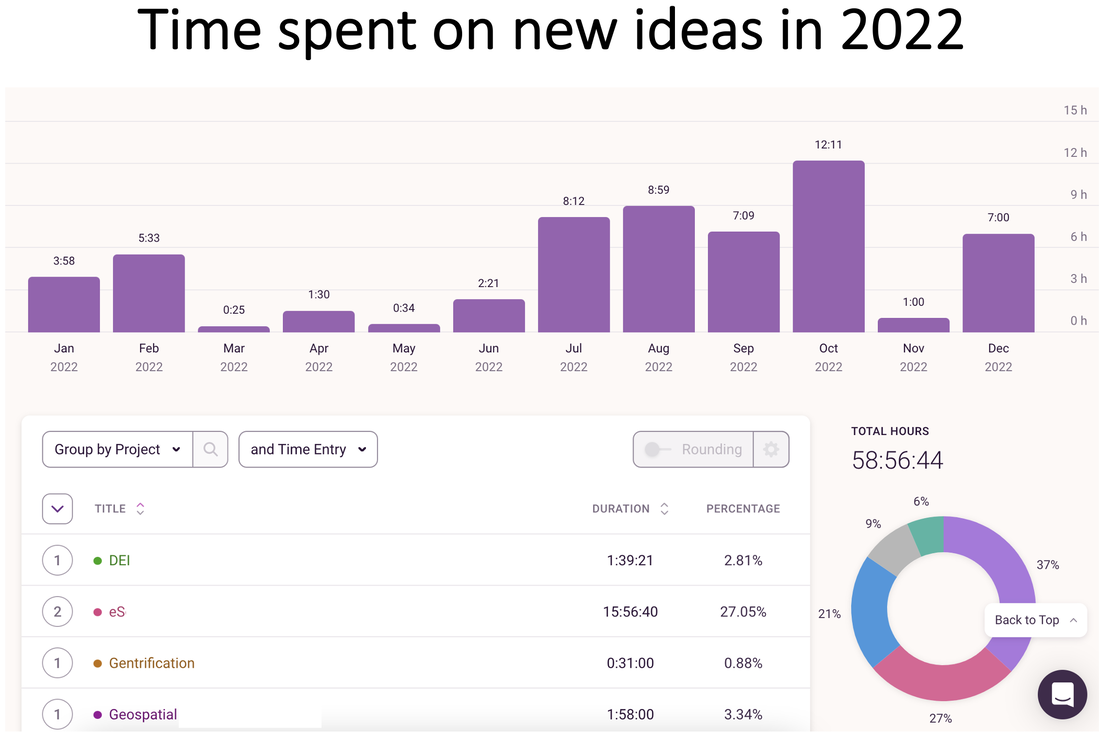 What's in a Number? |