|
Where did 2021 go? I know exactly where. If you know me or anything about me, you know that I love data. I track my workouts. I track my daily calorie intake and macros, and most importantly, I track the time I spend on various research projects. As 2021 comes to an end, I wanted to share some of the tracked data from my life. My hope is that this will be a useful sneak peek for current and future tenure-track assistant professors. Perhaps this may even be useful for those wanting to pursuing a goal in 2022, especially a fitness-related goal. Snapshot of what I did this year My biggest commitment in 2021 was my research projects. I spent 932 hours on my top 6 research projects this year! While I explored opportunities for new projects, it turned out that I spent 60% of my time on projects that continued from last year. Last year, in July-December 2020, I had already spent 610 hours advancing 3 of the top 6 research projects this year in terms of time commitment. In 2021, one of these continuing projects on online learning platforms was accepted for publication at the Journal of Marketing Research. Two were rejected in advanced rounds, and subsequently received an opportunity to revise at other journals (note to self: never give up). Interestingly, the research that I spent most time on took up about 37% of my effort this year. It has recently resulted in its first complete draft (coming soon). It also happens to be a paper about the privacy implications of tracking granular mobility data. 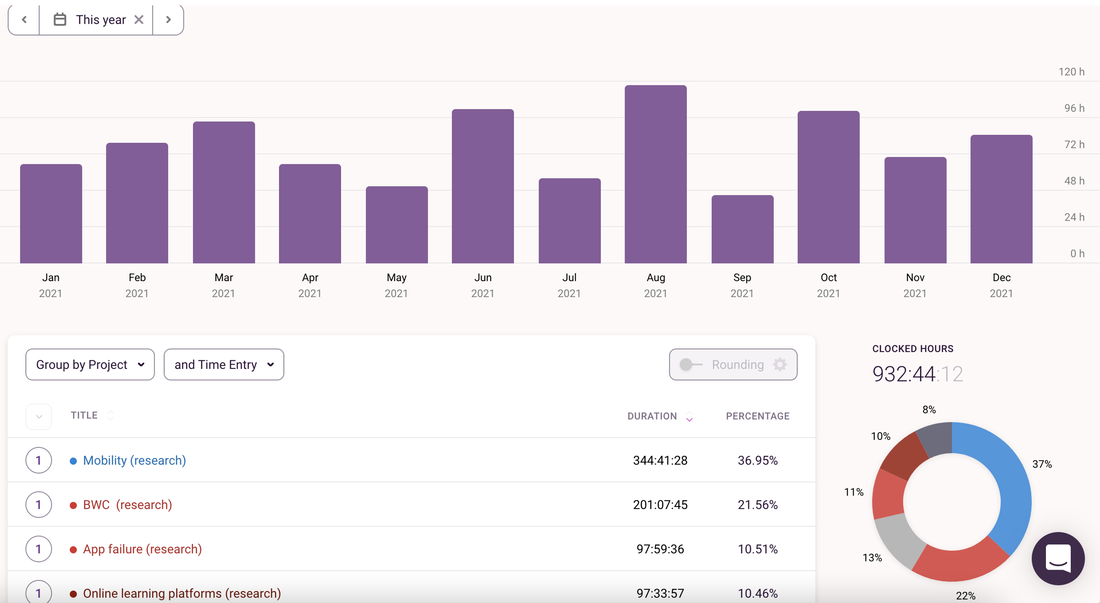 Now onto the tracked data from my other big commitment of 2021 -- health and fitness. I completed over 250 hours of workouts this year! My breakdown from the last 6 months shows that I spent 117 hours spent working out between July-December. Of these, more than 50 hours were at Orangetheory fitness, a popular group fitness class comprising treadmill, rowing and strength training intervals. In addition, I spent about 58 hours doing heavier weightlifting, with 60% lower body training. I have been going to group fitness classes for more than 10 years but this year, for the first time, I stepped under the barbell, going from body weight squats to over 160lbs barbell back squats in just a few months. 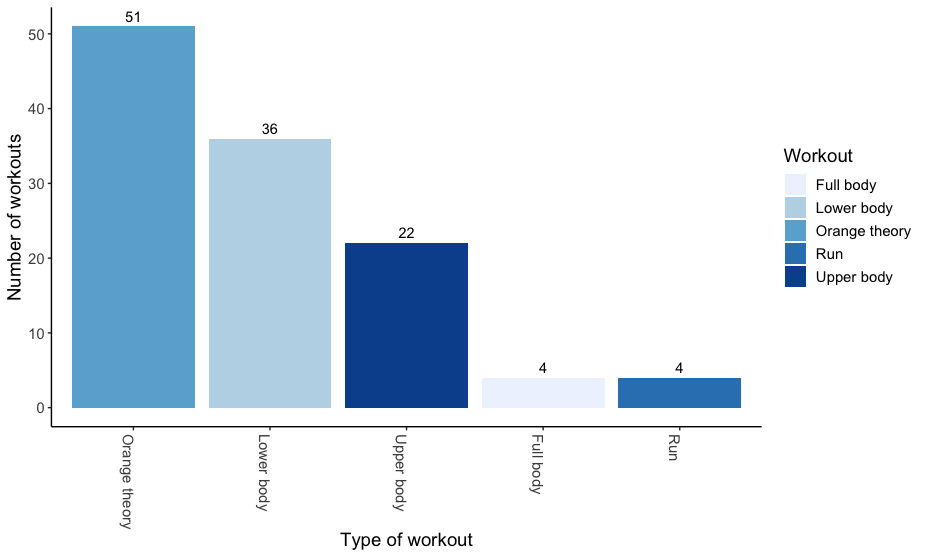 Since I also track my calorie consumption, what surprised me most was that I wasn’t eating any differently on my cardio vs. strength days, or upper vs. lower body days. The box plot below shows that I consumed very similar amount of total calories irrespective of the kind of workout I had that day. I'm curious to see how this split varies by macros, since I do make an effort to consume more carbs on lower body/heavier lifting days and keep carbs low on other days. 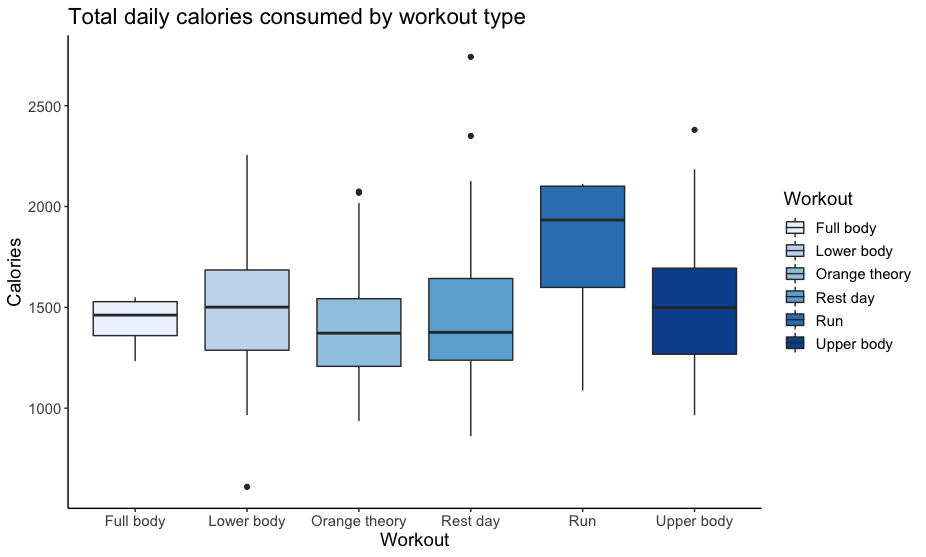 Results? Overall, it was quite rewarding to see that I started this year at 160lbs and closed it just under 140lbs with a 7% drop in body fat (between June and November). 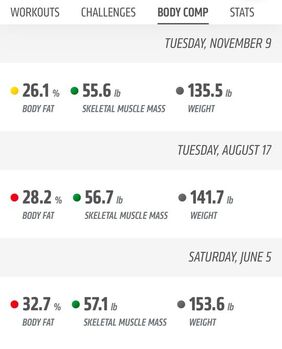 Did tracking everything cause me to be more productive or get more in shape? I’ll leave that question for a future paper once I can figure out an identification strategy. For now, enjoying the descriptives and looking forward to continuing the tracking trajectory in 2022!
How I collected these data Time spent on research projects: I use a mobile/web tool called Toggl that allows me to set up various categories of projects I work on. All I have to do is hit play when I begin working on a project and pause when I stop. Most of the times, I do remember to track it. If I forget to stop it, Toggl sends me a timely email nudge to go in and pause it, so I guess with some accuracy what time I stopped working. For the most part, I can correctly see where my time is going with some margin of error, of course. Fitness data: I use a combination of apps to track my fitness journey, including MyFitnessPal for nutrition, the Orangetheory app and heart rate monitor for OTF workouts, and my own filming skills (iphone camera, really) to keep track of non-OTF strength workouts. On June 16, 2021, I completed my first year at the Gies College of Business. It is hard to bucket this year’s “life lessons” into logical themes but I will try my best to make this relevant for other junior faculty and PhD students.
When I asked a few new assistant professors how their work and life changed when they went on from their PhD to their jobs, here are a few things they said:
My perspective and mindset, like with most things, was quite different on this topic. The major changes I noticed were: (a) New institution: I was now part of a whole new university system, a new business school, new department (duh!), (b) More resources: I had a lot more resources for my research and needed to learn the skills to best use them, and (c) Citizen Unnati: I was a citizen of my department in a bigger way and had a responsibility towards colleagues and also students who were either taking courses or working with me. Here is how these not-so-groundbreaking observations helped me in my first year as an assistant professor: (a) New institution
(b) More resources
(c) Citizen Unnati
Overall, my first year as a junior faculty pushed me to reframe my role, learn new skills, get to know amazing people at my school, and influence students in addition to focusing on my own research as I did during my PhD years. How was your experience? (This article originally appeared on https://giesbusiness.illinois.edu/news/2020/11/25/sony-s-playstation-5-or-xbox-series-x-backward-compatibility-with-older-games-plays-into-console-wars)  Sony and Microsoft have both upped their game with the release of their latest consoles, PlayStation 5 (PS5) and Xbox Series X this November. However, when it comes to backward compatibility with previous generation games, Microsoft’s Xbox has a head start.
“While PS5 is compatible with 99% of the games for PS4, the previous generation console, Xbox Series X goes far back with its backward compatibility feature. It spans multiple generations of games from the original Xbox, Xbox 360 and Xbox One,” said Unnati Narang, assistant professor of marketing at Gies Business. In a recent paper she co-wrote, Narang examines the effect of Xbox One’s backward compatibility feature on its previous and new generation games. “What we found in our research is that when Xbox One allowed compatibility with older Xbox 360 games in November 2015, the unit sales for the old console games decreased, but the revenues from both old and new generation console games increased. The revenue lifts came largely from more popular games,” added Narang. So, not all games benefit equally from backward compatibility? “The selective launch of compatibility for some games allowed us to understand these effects at the game level,” said Narang. “High-selling games, games with an ESRB rating of E (everyone), action games, and those with high user ratings proved to be the primary beneficiaries of backward compatibility among the older generation games." Narang and her co-author Venky Shankar also examined the spillovers to new-generation console games. In other words, what explained the positive impact of Xbox One’s backward compatibility on its own (new) games? The research used detailed data on individual gamers’ game and console purchases over three years, 2014-2017, from a large gaming retailer to understand the potential explanations for the spillovers. “The data revealed that those who already owned backward compatible games before 2015 were twice as likely to upgrade to the new console. Since these preowners no longer needed to buy old games they already owned, they also had more spending capacity to buy the new console games due to a budget effect,” Narang explained. Narang’s research shows that the effects of backward compatibility, although positive overall, may not apply evenly to all games and buyers. Managers should strategically launch backward compatibility based on their likely impact on sales as well as customer expectations. Unlike the Xbox, for PS5 most games are covered under backward compatibility with only a very short list of excluded games. “What we are seeing now is a move toward standardization in the gaming industry for backward compatibility. Competition between rival platforms often results in these standard wars,” says Narang. What does it mean for the future of console wars and the role of backward compatibility? “Console makers and publishers need to appreciate the complexity of the backward compatibility decision. New considerations, such as availability of multiple generations of games on the new console, playability on online gaming networks, and compatibility of disc and digital versions, will play a critical role going forward. PS5, for example, launched with a digital edition of the console, which isn’t compatible with the PS4 discs,” added Narang.  I enjoyed talking to our media folks @ Gies about my mobile marketing research, what got me thinking about a PhD 7 years ago, and the next steps in my academic life.
Interested? Read more on Gies News. The recent growth in structured and unstructured data combined with sophisticated techniques for leveraging these data for decision-making, creates huge opportunities for marketers. All business students can benefit from learning about marketing analytics and applying analytics techniques to real-world marketing problems.
I discuss more in my "coffee chat" with Joseph Yun, Research Assistant Professor of Accountancy and Director of the Data Science Research Service, UIUC: https://vimeo.com/452730158 Educators all over the world are currently facing a common challenge: How do we teach in the new COVID-19 environment?
One thing we have always had on our side as educators has been time. We have time to research the topics, to research pedagogical approaches, to design courses we will teach in future way in advance. We have time to think, to deliberate, to arrive at optimal solutions. However, with COVID-19, we have suddenly been thrust outside the old world we knew. Those who taught during the Spring semester know and appreciate how mid-way through the semester, instruction was moved completely online. You wanted more time to plan and design the online experience for your students? Well, too bad. Those of us (including me) who are teaching in Fall 2020 have more time but also a lot more uncertainty. Will classes be held purely online? Will there be an in-person element? What would a blended/hybrid course look like? By some estimates, 65% of colleges plan to re-open for the fall. However, "re-opening" will look drastically different in the new world. Colleges are already discussing how to enforce social distancing norms and masks in classrooms, with fair concerns surrounding their success in practice. Given the uncertainty for Fall 2020, what can you do as an instructor to be prepared to the extent possible? I have been in online education for nearly a decade now. I have worn many hats during this time: A high school teacher, course designer and marketer for online exec ed courses, a doctoral student, and now an assistant professor of marketing. While these many roles silently prepared me for the challenges we face today, there are no definitive answers right now. So, I've been asking peers and mentors. I have been enrolling myself in online courses. I've been talking to elearning teams, videographers, and experts at Coursera. I've been participating in an intensive 3-week program offered by the U of I elearning team. What am I learning about teaching in the online space? 1) Learn and own the tech: Campus elearning teams are swamped! In the ideal world, I would walk into a studio and deliver my content. The videographer will film it. Someone on the team will work on post-production and someone else will put it all together. Voilà! My online course is up and running. The reality is these teams are swamped right now. Consult them, ask them specific questions, show them stuff and get an opinion. Other than that, learn and own the tech. Here are some more tips from Coursera on how to record home videos. I invested in inexpensive tripod and lapel mics. It also helps to record shorter videos segments in fewer cuts so post-production is easy and at the same time, the content is nicely chunked and organized for students. 2) Survey other courses: I have found it super helpful to talk to instructors who have been successful at teaching online (even in the pre COVID era) and surveying their courses. These courses can be MOOCs or online LMS for degree courses. These courses can be within your discipline or beyond. When you survey them, think like a designer. Reverse engineer it. Look for elements that you would never have thought of but that can be central to learning in a highly distracting online environment. For example, my colleague Aric Rindfleisch teaches a popular Coursera MOOC on digital marketing that offers a practice quiz at the end of each module in addition to a graded quiz. These practice quizzes can serve as a diagnostic tool for the instructor as well as a self-assessment tool for learners. Similarly, economics professor Jonathan Meer at Texas A&M University and his co-instructor in their online course have a full-fledged course orientation module #0 setup as a pre-requisite. Course LMS should be super intuitive, right? But as he points out in some of their videos, students can often miss a critical link to the module videos, central to their learning and not notice it as half the semester goes by. Jonathan summarizes his key lessons from online teaching in this video I HIGHLY RECOMMEND on how to set up an online course. Organize, prepare, plan your scripts, include a co-instructor when possible, use other forms of digital media including podcasts or videos to break the monotony. Host at least a few live zoom sessions with your students so they can see you are a real human being. 3) Include and make LIVE interactions fun: There is value in incorporating a few live sessions over and above the asynchronous videos. Whether these are online or in-person, plan these well and incentivize students to show up and participate. One of the best ideas I have received on garnering engagement during these online live sessions came from Elizabeth Luckman, Clinical Assistant Professor of Business Administration at Gies. Elizabeth opens a shared google doc that groups of students simultaneously work on in breakout rooms in zoom. In her own words: "I did a “reflection exercise” at the beginning of the live session. I had four reflection questions I wanted students to address, and I created a google spreadsheet with the same number of tabs as groups. Then I put them in breakout rooms and in those rooms, they had to type answers into the doc. So that means that even though they were in breakout rooms, I could see (and they all could see) what each of the other groups was doing. I had never done it before but it worked really well! The crowdsourcing doc that I showed is live all the time, and they can add to it at any time. My goal is that they can use that information for their final projects - and also just have this cool resource that they can download and save after the class ends. Keeping discussion going during live sessions is rough. My experience is that smaller numbers of students in live sessions, the google doc during breakout groups, and (sadly) incentivizing discussion is sort of the right mix." To better teach online, we must first learn to learn ourselves. Overall, don't fret! Accept that teaching in the new world will look different. Accept that it will require unlearning and relearning, and higher investment of time and energy. Be patient with yourself but open to learning new tools and techniques. Try to place yourself in the shoes of your students and wondrous new insights will emerge!  Five years. 2015-2020.
When I started my PhD five years ago, like any new incoming student experiencing the academic world for the first time, I had naive expectations about research and doctoral education. In this article, I share my own experience and challenge five myths new students often have about getting a PhD: 1) It is all about grand ideas. Grand ideas are a good start. However, execution of a few good ideas is what gets you through. When I started my PhD in Marketing, I had the grand vision of researching how the mobile-first world impacts consumers and firms in different domains, including retail (how we shop), education (how we learn), and healthcare (how we access health services). Many first year PhD students come in with a grand vision and think they must pursue it all. When defining the scope of my doctoral research, it helped to keep three things in mind:
2) The dissertation is the be-all-end-all of my PhD research and must have lasting impact on the field. There are differing perspectives and philosophies on what a dissertation is and should contain. I personally found it helpful to conceptualize my dissertation as a set of related papers that together fairly represent my broad interest areas, demonstrate my empirical skills, and introduce sufficiently new ideas or insights to an existing body of work. Often, PhD students get caught up in the "impact" trap -- where we want to create impactful research right away. Consequently, no manuscript or draft seems "good enough." The danger is a resulting research paralysis, a kind of a "writer's block" that prevents progress. Along my PhD journey, lots of people gave me good practical advice that helped get my first drafts done. Three senior academics at different times told me:
3) Unless I go to a top school or find a well-known advisor, it doesn't count. Incoming new students often place tremendous weight on top schools and popular advisors. While these factors can help, ultimately your peers, colleagues and recruiters are all looking for signals about YOU. Who are you independent of your advisor or school? What do you care about? Have you demonstrated research acumen, perseverance and initiative? Over the years, as I have seen PhD students who entered a PhD program only to find their advisor leave their job at the university or department management and budgets severely changed, this perspective may be a good reminder to take ownership of their projects despite all odds as they work to improve their circumstances. 4) Unless my advisor contributes, I cannot make progress. Let's face it. Advisors are busy. They are constantly juggling teaching, traveling, multiple projects, and sometimes, even consulting. Waiting for your advisor to do the work for you is dangerous even if they have the best of intentions. Do your part. Do as much as you can. Go out there and find the help you need -- online, offline, at the library. Most of the problems you are waiting on your advisor to solve for you may have been solved before. Take your best solution to your advisor instead of just the problem statement. You will be surprised how much faster things are able to move. 5) More number of manuscript will help me succeed. Advanced and finished projects with a fair pipeline are much better than a bunch of loosely connected works-in-progress or working papers. Prioritize prioritize prioritize. Yes, we all need some "fun" projects and starting new projects is always fun. As they age and get further along in the review process, projects tend to become drudgery for anyone. That's the time to push through. Instead of constantly starting new projects, finish the ones you start. Every research has weaknesses and the review process is geared to bring them up. Preempt them. Acknowledge them. Fix them to the extent possible. Turn those manuscripts back in. If you are going to get it rejected, might as well find out sooner than later. Finally, along the way, have fun! Make friends. Explore your campus. Reach out to people. Talk to people at conferences. Talk to people outside your field. Ask lots of questions. Help others. The journey is so much more memorable that way. Best! |

